In binary classification problems, we try to predict y=1 representing for example default or cancer. How can we evaluate if our models are good or bad?
Positives are the number of y=1 in our dataset. True positives are number of correct positive predictions. Said another way: true positives are the number of datapoints where we predicted 1 when the actual value indeed was 1. Likewise, negatives are the number of y=0 in our dataset. True negatives are the number of correctly predicted negatives.
Denote Positive by P, Negative by N, True as T and False as F. Using this notation True Positive is abbreviated TP, and so on. Ideally, you want many TN and TP combined with very few FN and FP. Of course, we cannot have it all: there is a trade-off between FP and FN (or as the statisticain would say: “a trade-off between type-I error and type-II error”).
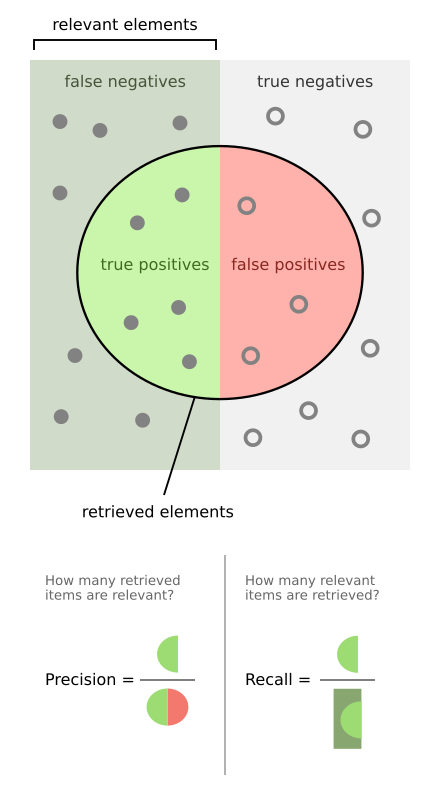
A confusion matrix (see image below) gives you a good picture of how your classifier is performing. It summarizes the number of TN, TP, FN, FP. We wish to have as many as possible in the upper left and lower right.
| Prediction = 0 | Prediction = 1 | |
|---|---|---|
| Actual = 0 | TN | FP |
| Actual = 1 | FN | TP |
Total number of positives = P = sum of the row Actual = FN+TP. The matrix allows us to compute various classification metrics, and these metrics can guide our model selection. Some evaluators are listed below.
- Accuracy = (TP + TN) / (P+N).
- Precision = TP / (TP + FP)
- Recall = Sensitivity = tpr = TP / P
- fpr = FP / N
By looking at the table above (or image below) we can understand what they measure.
Read more on how to evaluate binary classifiers on Wikipedia.
